

what is inference in machine learning — A Complete 2025 Guide for Engineers, Product & Business
What is inference in machine learning — Inference is the runtime phase when a trained model turns new inputs into predictions or outputs. This guide covers production pipelines, LLM specifics, edge inference, observability, and practical optimization recipes (quantization, distillation, caching) you can apply today.
What is inference in machine learning? (Definition + quick example)
Inference is the process of applying a trained model to new inputs to generate predictions or outputs. While training adjusts model parameters based on labeled data, inference is where those fixed parameters are used in production to make decisions or create content.
Minimal code example (scikit-learn)
import joblib
model = joblib.load("spam_clf.joblib")
print(model.predict(["Congratulations — you won a prize!"]))Micro example: A spam classifier trained offline is deployed as an inference endpoint; each incoming email is passed to that endpoint, which returns a prediction such as spam or ham.

Why inference matters in 2025
Inference is the product-facing phase of machine learning where value is created and recurring costs are realized. Two 2025 trends raise its strategic importance:
- Economic pressure: Many organizations report rising inference costs (per-query or per-token pricing in LLMs). This changes product design, pricing, and rate-limiting strategies.
- Edge & hybrid architectures: As latency and privacy expectations grow, teams shift workloads to edge devices or hybrid cloud/edge models to reduce latency and data egress.
Because inference impacts UX and recurring cost, it’s essential to treat inference engineering as a core discipline: measuring tail latency, modeling per-request cost, and optimizing both software and hardware for production loads.
Training vs Inference — a compact comparison
When asking what is inference in machine learning, contrasting it with training helps: training produces or updates model weights, while inference uses those weights to score unseen inputs.
| Aspect | Training | Inference |
|---|---|---|
| Goal | Learn/update weights | Predict/generate outputs |
| Compute | High, parallel (GPUs/TPUs) | Per-request, latency-sensitive |
| Latency | Minutes → hours (batch) | ms → seconds (real-time) |
| Cost profile | Heavy, episodic | Recurring per-request/token |
| Data | Large datasets, many epochs | Single example or small batch |
| Hardware | Multi-GPU/TPU clusters | CPU/GPU/accelerator/edge chips |
When to focus where: Optimize training when model quality is the bottleneck; optimize inference when latency, cost-per-request, or scalability are the blockers.
Types of inference: real-time, batch, streaming (and hybrid)
Real-time (low-latency)
Use cases: fraud detection, interactive recommendations, chatbots. SLOs are often expressed at p95/p99 latency. Real-time systems must be designed for tail latency and graceful degradation.
Batch (throughput-first)
Use cases: nightly re-scoring of recommendations, bulk ETL enrichment. Batch jobs maximize throughput and cost-per-item efficiency rather than per-item latency.
Streaming (continuous/online)
Use cases: clickstream scoring, real-time personalization where features are computed per event or per window. Requires careful windowing and state handling.
Hybrid patterns
Many real-world systems combine batch precomputation (heavy features, embeddings) with real-time scoring for freshness. Feature stores and online caches are common components of hybrid architectures.
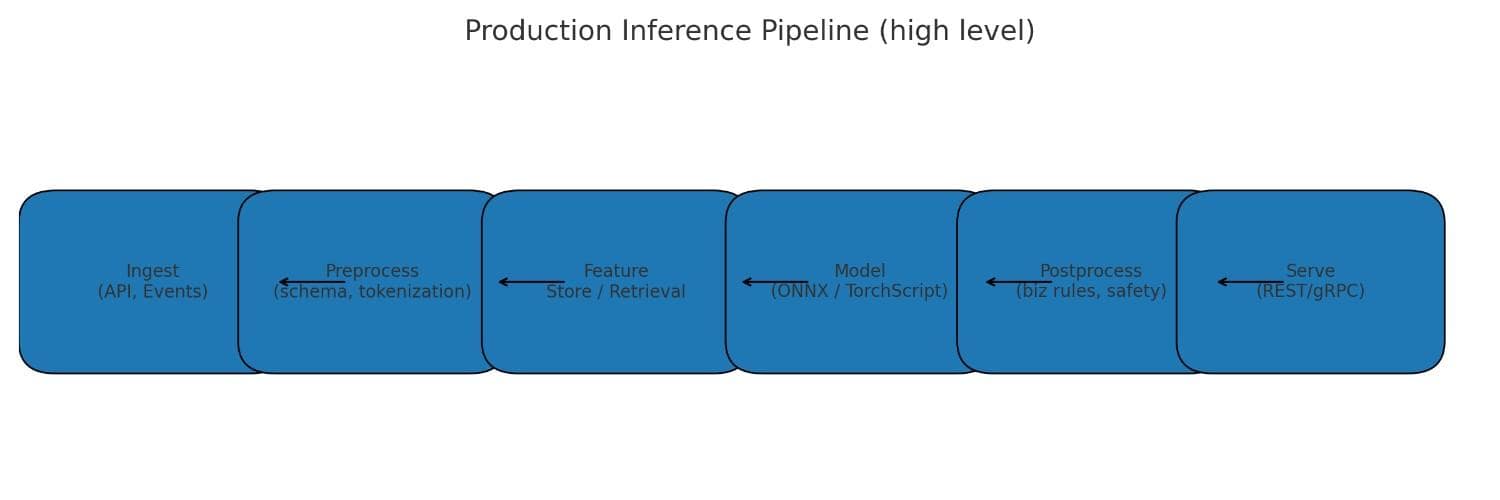
Components of a production inference pipeline
- Model artifact: ONNX, TorchScript, TensorFlow SavedModel, or vendor bundles.
- Input validation & feature pipeline: schema checks, type validation, online feature lookups.
- Preprocessing & tokenization: deterministic transforms and tokenizer consistency (critical for LLMs).
- Serving layer: REST/gRPC endpoints, inference servers (Triton, TorchServe), serverless functions, or edge runtimes.
- Postprocessing & business rules: thresholds, mapping scores to actions, safety filters.
- Telemetry & logging: latency percentiles, error types, prediction logs and sample capture (with privacy controls).
- Caching & rate limiting: reuse identical responses and protect against extraction attacks.
Versioning, CI/CD for model artifacts, and automated tests for preprocessing parity are crucial to avoid silent failures when the model is in production.
Performance & cost: latency, throughput and tradeoffs
Key metrics to measure and manage:

- Latency percentiles — p50, p95, p99; tail latency (p99) often determines user experience.
- Throughput — requests/sec or tokens/sec for LLMs.
- Per-request cost — CPU/GPU time, memory, network, and retrieval overhead for RAG.
Practical levers
- Batch requests when latency is flexible to increase throughput and reduce per-item cost.
- Use reduced precision (quantization) or smaller distilled models to shrink compute per call.
- Cache high-frequency answers or retrieval results for RAG flows.
- Model cost as: (instance $/hr × utilization × time per request) / requests per hr + storage + network.
Hardware choices for inference (CPU, GPU, TPU, NPU)
Selection depends on model size, request pattern, latency SLOs, and cost.
CPU
Best for small models or many low-concurrency requests where GPU overhead is not justified.
GPU
Good for large models or when batching significantly improves throughput (LLMs, vision). GPUs excel at parallel compute.
TPU / accelerators
High throughput in supported cloud environments; useful for large-scale batched inference workloads.
NPUs & mobile accelerators
Optimized for on-device inference at low power; important for privacy-preserving and offline scenarios.
In 2025, there is a clear trend toward edge inference, enabled by better silicon and frameworks; evaluate if moving part of the workload to edge reduces latency and cost for your use case.
Practical optimization recipes
Quantization (INT8, FP16)
Reduce numeric precision of weights/activations to lower memory and increase throughput. Apply post-training quantization or quantization-aware training depending on accuracy sensitivity. Frameworks: ONNX Runtime, TensorRT, PyTorch quantization utilities.
Pruning & sparsity
Remove redundant parameters or neurons. Structured pruning (channels/blocks) yields hardware-friendly speedups when supported by runtime.
Distillation
Train a smaller student model to mimic a larger teacher. Students can often match much of teacher accuracy with much lower inference cost.
Operator fusion & graph optimization
Fuse adjacent operations to reduce kernel overhead and memory movement. Use optimized runtimes (TensorRT, ONNX) to apply these transforms automatically.
Token-level optimizations for LLMs
Speculative decoding, early exit, caching, and token pruning can reduce per-session compute for generative models.
Special considerations for LLMs and generative models
LLM inference is tokenized, streaming and often billed by token; as a result, cost, latency, and UX interact differently than with classification models.
Tokenization & prompt costs
Cost scales with prompt length and generated tokens. Normalize prompts, minimize unnecessary context, and use retrieval to reduce prompt sizes.
Streaming & UX
Clients expect partial outputs quickly. Implement streaming with backpressure and client-side merging for best UX.
RAG (Retrieval-Augmented Generation)
Retrieval adds latency and cost (vector DB lookups, scoring). Cache frequently used retrievals and consider hierarchical retrieval to reduce calls.
Caching
Cache canonical prompts or embeddings to avoid repeated expensive decoding for common queries.
Safety
Filter outputs, sanitize PII, and incorporate human review paths for high-risk actions.
Edge & on-device inference (mobile, IoT)
Edge inference reduces latency and keeps data local (privacy), but requires model compression and hardware-specific optimizations.
Approaches for edge:
- Convert models to TFLite / Core ML / ONNX for mobile runtimes.
- Apply quantization and operator mapping that matches the device’s NPU/accelerator.
- Use hybrid cloud-edge patterns: small local models for offline decisions + cloud fallback for complex tasks.
Observability & reliability — what to monitor
Essential metrics:
- Latency percentiles (p50, p95, p99)
- Throughput (requests/sec, tokens/sec)
- Error rates and exception counts
- Input distribution drift and schema violations
- Calibration metrics (Brier score, confidence histograms)
Set alerts for p99 latency regression and sudden input distribution changes. Implement automated rollback triggers for large accuracy or safety regressions.
Safety, fairness & legal considerations at inference time
Key concerns:
- Bias amplification: Models can amplify biases at inference; monitor group-level outcomes and apply postprocessing where appropriate.
- Regulation & auditability: For automated decision-making, you may need to provide explanations or human review depending on jurisdiction.
- Human-in-the-loop: For high-risk decisions, require human sign-off or secondary verification.
Security & privacy risks specific to inference
Common risks:
- Model extraction attacks: Repeated queries can reveal model behavior; mitigate with rate limits and query monitoring.
- Membership inference: Attackers may try to determine whether a data point was in training data; consider differential privacy techniques during training.
- Data leakage: LLMs can inadvertently reveal sensitive training data — use filtering and output sanitization.
Testing, benchmarking & MLPerf
Testing strategy:
- Unit tests for preprocessing and tokenizer parity.
- Integration tests with synthetic and adversarial inputs.
- Load tests that exercise p95/p99 under realistic traffic.
Benchmarking: MLPerf Inference is an industry standard for comparing latency and throughput across hardware and models; use it to inform hardware buys and procurement decisions.
Common pitfalls & short remedies
- Mismatched preprocessing: Keep preprocessing shared between training and serving; unit-test it.
- Input drift: Monitor and trigger retraining or manual review when distributions change.
- Hidden feature leakage: Audit feature pipelines for inadvertent use of future or sensitive data.
- Over-batching: Balance batching with latency SLOs to avoid user-visible delays.
Quick remedies: if p99 latency spikes, examine queue/backlog and recent deployments, then scale or roll back accordingly. If accuracy drops, capture failing inputs and run offline validation against previous models.
Case studies
Fraud detection (real-time)
Architecture idea: Streaming ingestion → online feature store → low-latency model endpoint → action or human review.
Key metrics: false negative rate, decision latency (ms), cost/decision.
Notes: Ensure feature freshness and a human review mechanism for high-risk cases.
Recommendation (batch + real-time)
Architecture idea: Nightly batch job to update candidate embeddings + real-time re-ranking using a small low-latency model.
Key metrics: click-through rate, recommendation latency, cache hit ratio.
LLM chat assistant (streaming + RAG)
Architecture idea: User prompt → retrieval (vector DB) → prompt assembly → streaming LLM → client. Monitor token use and latency to first token.
Key metrics: tokens per session, cost per session, latency to first token, hallucination rate.
Tools & platforms
Commonly used tools for inference:
- Serving & runtimes: Triton Inference Server, TensorRT, ONNX Runtime, TorchServe, TensorFlow Serving.
- Cloud endpoints: AWS SageMaker Endpoints, Google Vertex AI, Azure ML Endpoints, Hugging Face Inference API.
- Edge & mobile: TensorFlow Lite, Core ML, TFLite Micro.
- Benchmarks: MLPerf Inference.
Conclusion & next steps
Inference is where machine learning delivers value — but also where recurring cost, latency, and user experience intersect. In 2025, treat inference as a product engineering discipline:
- Measure: collect p99 latency, cost per request/token, and input drift metrics.
- Optimize: apply one optimization at a time (quantization, caching, or distillation) and measure its impact.
- Observe & secure: implement logging, drift detection, and attack mitigations.
- Choose hardware wisely: evaluate CPU vs GPU vs accelerators and consider edge where it reduces latency or preserves privacy.
Start with a small benchmark endpoint, gather production metrics for a week, then iterate using the optimization recipes described above.
FAQs
- Is inference the same as prediction?
- Yes — a prediction is the output produced during the inference process.
- Can inference update model weights?
- No. Inference uses fixed weights. Updates happen during training or fine-tuning.
- How do I reduce LLM inference cost?
- Normalize prompts, cache embeddings/responses, use retrieval with smaller models, and apply quantization or speculative decoding.
Further reading
- NVIDIA TensorRT — optimization tools for GPUs and inference acceleration.
- TensorFlow TFX — production ML pipelines and serving patterns.
- Related: Full-Stack Developer Roadmap in 2025
- Related: AI vs Human Intelligence in 2025
Ok