

Functional Programming Paradigm: Principles, Effect Systems & AI Workflows (2025)
Author: Usman Shaukat — Published: 2025-09-01
TL;DR — What the functional programming paradigm is (short answer)
Quick answer: The functional programming paradigm treats programs as compositions of functions. It favors pure functions (no hidden side effects), immutable data, and building systems by composing small, testable pieces. In 2025, functional ideas are practical: they make concurrent systems safer, help build reproducible ML pipelines, and pair well with effect systems and AI-assisted development.
Jump to: Effects & effect systems • FP + AI workflows • Migration playbook

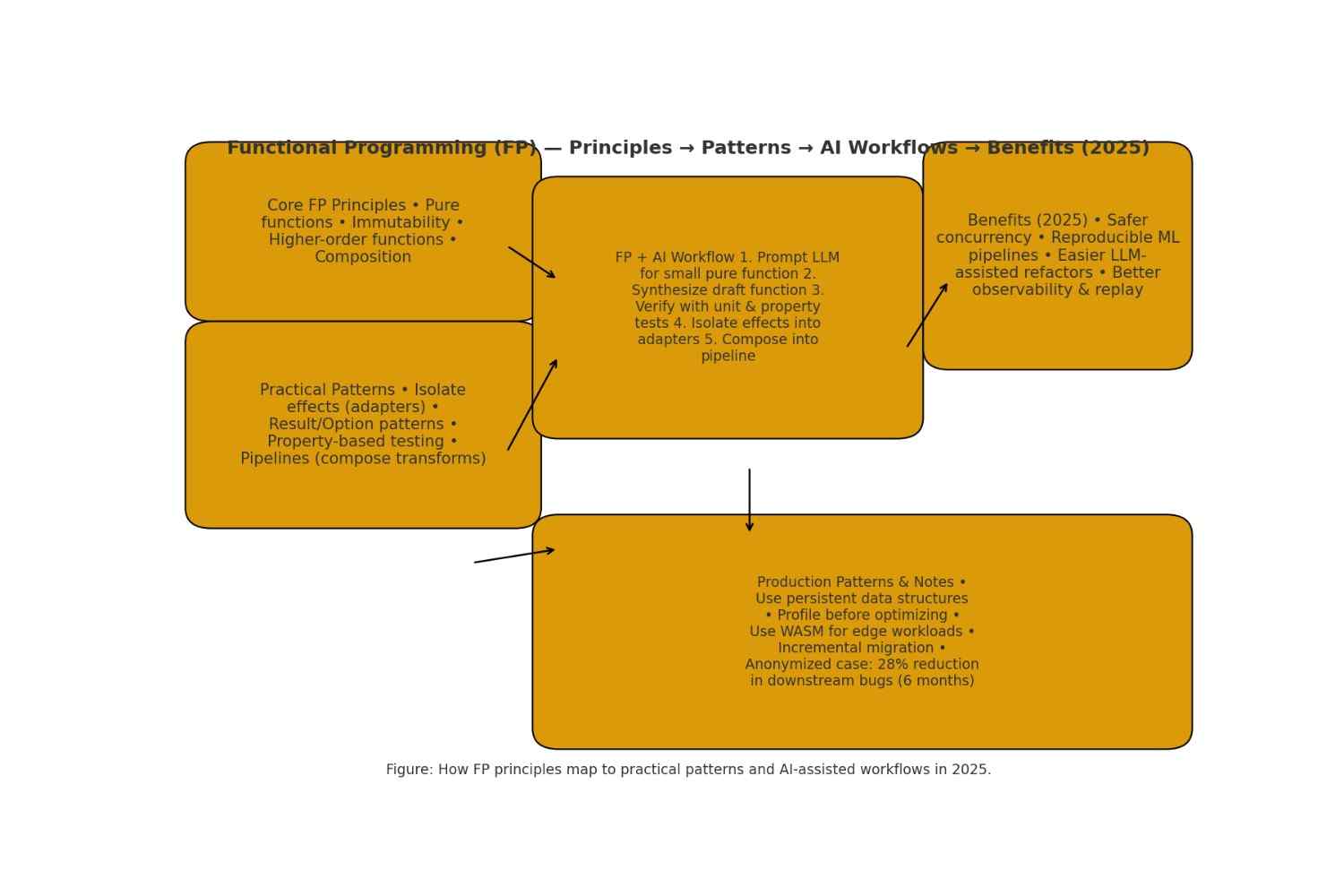
What is the functional programming paradigm?
Simple definition (non-technical): The functional programming paradigm is a way of building software by composing small functions that each do one thing and avoid hidden side effects.
Technical definition: FP models programs as pure computations: functions are first-class values, data is immutable by default, effects are isolated, and composition and higher-order functions are used to build complex logic from smaller pieces. FP traces back to lambda calculus and later matured with languages like Haskell and ML; parts of FP (like lambdas, higher-order functions, map/filter/reduce) are now common in mainstream languages.
Why this matters: When logic is expressed as pure functions, it’s easier to reason about, test, and parallelize. Side effects (like database writes or network calls) are pushed to the edges of the system, making the core behavior predictable and easier to test.
| Term | Plain meaning |
|---|---|
| Pure function | Always same output for same input, no hidden changes |
| Immutability | Data structures aren’t changed in-place |
| Higher-order function | Functions that take/return other functions |
| Effect | Any interaction with the world (IO, randomness, state) |
| Composition | Building complex behavior by combining small functions |
Core principles of the functional programming paradigm
Pure functions & referential transparency
A pure function is easy to test and reason about because you can replace the function call with its return value everywhere. Pure code yields simpler debugging, straightforward caching/memoization, and easier parallel execution.
Immutability
Immutable data avoids shared-mutation bugs. Instead of editing an object in-place, functions return new objects. Immutable structures are especially useful in concurrent systems and event-sourced architectures.
First-class and higher-order functions
Functions can be passed like values. Higher-order functions let you abstract common patterns: map, filter, and reduce are canonical examples. They make code concise and composable.
Recursion and tail-call optimization
FP uses recursion to express loops. Tail-call optimization (TCO) makes recursion efficient, but TCO is not guaranteed in all runtimes — be pragmatic and use iterative patterns when TCO isn’t present.
Lazy vs eager evaluation
Lazy evaluation defers computing values until needed; this reduces wasted work and can express infinite data flows as streams. Many languages provide lazy primitives (generators in Python, iterators in JS).
Function composition & pipelines
Compose small functions into pipelines that process data step-by-step. This leads to clear, testable stages: parse → normalize → transform → output.
Why the functional programming paradigm matters in 2025
By 2025, several forces make FP practical and valuable:
- Concurrency and multicore compute: Pure functions and immutability reduce shared-state bugs and make parallelism safer.
- MLOps & reproducibility: FP-style pure transforms make data processing deterministic and easy to test and reproduce across environments.
- Effect systems maturity: New language features and libraries (algebraic effects, typed effect-tracking) help manage side effects clearly, enabling safer composition of effectful code.
- AI-assisted coding: LLMs are better at suggesting single-function implementations or refactors; FP’s small, pure units fit well into AI workflows where the model proposes a function and engineers verify and compose it.
- Tooling & compilation: Better toolchains (including WebAssembly targets for FP runtimes) make FP more practical in diverse deployment environments.
Tradeoffs: FP can have a learning curve, and naive immutability can cause performance issues (excess allocation). The pragmatic approach mixes FP style for business logic while isolating effects and performance-critical code.
Functional programming paradigm in mainstream languages
Haskell — pure FP
Haskell is pure and lazily evaluated, with a strong type system. It’s ideal for high-assurance code, DSLs, and academic/industry proofs-of-concept.
OCaml / F# — typed FP in industry
These languages combine performance and typed FP features. They’re used in finance, compilers, and high-throughput services.
Elixir / Erlang — FP for concurrency
The BEAM (Erlang VM) is designed for fault-tolerant, concurrent systems. The actor model and supervision trees are valuable when reliability matters.
Scala / Kotlin — hybrid FP/OO
These JVM languages let you mix FP and OO. Libraries like Cats (Scala) bring algebraic abstractions to practical apps.
Java / C# — functional features
Modern Java and C# added lambdas, streams, and pattern matching. These features let you write FP-style code without leaving the platform.
JavaScript, Python, PHP — pragmatic FP
Most teams use FP idioms in these languages: higher-order functions, map/filter, immutability patterns. This is often the fastest path to benefit from FP without a full rewrite.

| Language | FP level | Best suited for |
|---|---|---|
| Haskell | High | DSLs, high-assurance logic |
| Elixir / Erlang | High (concurrency) | Real-time, fault-tolerant systems |
| Scala / Kotlin | Medium-High | JVM FP with interop |
| JS / Python / PHP | Medium | Web, ETL, ML glue code |
Effects & effect systems in the functional programming paradigm
This is a priority section for 2025. Effects are the real-world operations: IO, state changes, randomness, exceptions. The key design goal is to keep core logic pure and move effects to controlled boundaries.
Why isolate effects?
If your core logic is pure, you can test it deterministically. Effects then live in small adapter modules (DB, network, file system). That gives you replayability and safer composition.
Monads — the practical view
Monads are an abstraction for sequencing computations that carry context (like possible failure or IO). Practically you can use Result-like or Option-like wrappers to make failure explicit and composable.
Algebraic effects & handlers
Algebraic effects let you declare effectful operations (for example, readLine or getTime) and separately provide handlers that implement those operations. Benefits: decoupling, easier testing (swap in mock handlers), and safer composition.
Practical examples (Result-style)
Below are compact Result-style patterns demonstrating how to make failures explicit.
// JavaScript (Result-style)
const Ok = v => ({ ok: true, value: v });
const Err = e => ({ ok: false, error: e });
function divide(a, b) {
if (b === 0) return Err('division_by_zero');
return Ok(a / b);
}
const r = divide(10, 2);
if (r.ok) console.log(r.value);
else console.error(r.error);
# Python (Result-style)
def divide(a, b):
if b == 0:
return (False, "division_by_zero")
return (True, a / b)
ok, val_or_err = divide(10, 2)
if ok:
print(val_or_err)
else:
print("Error:", val_or_err)
<?php
// PHP (Result-style)
function divide($a, $b) {
if ($b == 0) return ['ok' => false, 'error' => 'division_by_zero'];
return ['ok' => true, 'value' => $a / $b];
}
$r = divide(10,2);
?>These patterns make failures explicit and easier to compose without throwing exceptions everywhere.
The functional programming paradigm + AI (2025 workflows)
AI code assistants are now common. They work well with FP because FP emphasizes small, single-purpose functions — ideal units for LLM synthesis. Use AI for suggestion and draft generation, but always verify using tests and code review.
How AI helps FP work
- Synthesizes small pure functions from docstrings or examples.
- Suggests refactors to more composable designs.
- Generates unit and property-based tests.
- Proposes compositions and pipelines using existing primitives.
Recommended safe workflow
- Prompt: Ask the model for a small pure function with examples and edge cases.
- Synthesize: Accept AI output as a draft.
- Verify: Run unit tests and property-based tests.
- Isolate effects: Make sure side effects live in adapters.
- Compose: Integrate the verified function into your pipeline.
Worked example (conceptual)
Prompt the assistant to write a pure function `normalizePhone` that returns only digits and preserves a leading `+` when present. Then run property-based tests that assert idempotency (applying the function twice is the same as once). This catches edge cases the model might miss.
Functional programming paradigm for ML and data pipelines
FP fits ML pipelines nicely because transforms are typically pure: map raw input → cleaned data → features. The training step is effectful and belongs at the boundary.
Recommended structure
- Pure transforms: parsing, normalization, deterministic feature derivation.
- Deterministic feature generation: no randomness unless injected and controlled.
- Effectful training: isolate training, model storage, and telemetry in adapters.
# Python: small pipeline example
from typing import Dict
def parse(row: Dict) -> Dict:
row['price'] = float(row['price']) / 100.0
return row
def extract_features(row: Dict) -> Dict:
return {'id': row['id'], 'price': row['price']}
# Orchestrator only iterates and calls pure functions
Benefits: reproducibility, easier debugging via replays, and straightforward unit testing.
Functional programming paradigm in distributed & cloud-native systems
FP maps well to event-sourcing and immutable logs: store events append-only, use pure processors to build snapshots, and run effect adapters to persist outcomes or call services. The actor model (Elixir/Erlang) remains strong for highly available concurrent systems.
Observability & debugging
- Log only in effect adapters.
- Propagate correlation IDs as immutable fields.
- Replay events using pure processors to reproduce bugs.
Migration & adoption playbook for the functional programming paradigm
This stepwise plan minimizes risk and gains measurable wins.
When to adopt features vs full rewrite
Prefer adopting FP features incrementally unless the codebase is unmaintainable and a rewrite is justified.
Stepwise plan
- Step 0 — Inventory: find stateless modules, ETL transforms, validators.
- Step 1 — Extract pure functions: move business logic into pure functions, keep adapters thin.
- Step 2 — Add testing: unit tests and property-based tests for invariants.
- Step 3 — Isolate effects: make adapters for DB/HTTP/FS; core returns descriptors or pure results.
- Step 4 — Rollout: use feature flags or dark launches; measure KPIs (bug rate, MTTR, cycle time).
Team adoption
Run short workshops, pair program refactors, and use a code-review checklist that favors pure core logic and explicit effects at boundaries.
Performance, optimization & WebAssembly (WASM) for FP
FP can be efficient if you are pragmatic about data structures and runtimes.
Considerations
- Immutability cost: naive copying increases allocations — use persistent structures where needed.
- Garbage collection: short-lived objects can stress the GC; profile and choose suitable runtimes.
- Tail recursion: use iterative patterns when TCO is absent.
WASM
Compiling FP code to WebAssembly is increasingly practical for edge workloads. Use WASM when you need predictable startup and sandboxed execution.
Benchmarking tips
- Avoid microbenchmarks; use realistic traces.
- Measure end-to-end latency and memory behavior.
- Profile before optimizing.
Testing, property-based testing & verification
FP makes tests simpler because pure functions are deterministic. Property-based testing is high-leverage in FP: define invariants and let the framework explore many inputs.
Python — Hypothesis example
# pytest + hypothesis
from hypothesis import given, strategies as st
def normalize_phone(s: str) -> str:
return ''.join(ch for ch in s if ch.isdigit())
@given(st.text())
def test_normalize_idempotent(s):
assert normalize_phone(normalize_phone(s)) == normalize_phone(s)
JavaScript — fast-check example
// fast-check + Jest
const fc = require('fast-check');
function normalizePhone(s) { return s.replace(/\D+/g,''); }
fc.assert(fc.property(fc.string(), (s) => {
return normalizePhone(normalizePhone(s)) === normalizePhone(s);
}));
Property tests find edge cases and generate minimal failing examples. If you lack a property-testing library in a language, emulate fuzzing, but prefer proper ports (Hypothesis, fast-check, etc.).
Formal verification
Formal proofs are expensive and usually reserved for critical systems; for most services, unit tests + property-based tests + CI deliver high-quality results.
Common pitfalls & anti-patterns when adopting the functional programming paradigm
- Over-abstraction: don’t hide intent with complex type trickery.
- Premature purity: sometimes orchestration is naturally stateful — keep it pragmatic.
- Big rewrite attempts: migrate incrementally and measure outcomes.
- Leaky abstractions: don’t mix side effects into your pure core.
- Performance ignorance: profile and optimize with data-driven decisions.
Hands-on tutorials & code recipes
Recipe 1 — JavaScript: compose data transforms
// pipeline.js
const pipeline = (x, ...fns) => fns.reduce((v, f) => f(v), x);
const parse = s => JSON.parse(s);
const addTax = items => items.map(i => ({ ...i, priceWithTax: i.price * 1.1 }));
const raw = '[{"id":1,"price":100},{"id":2,"price":200}]';
const out = pipeline(raw, parse, addTax);
console.log(out);
Recipe 2 — Python: ETL pure transforms
# transforms.py
from typing import Dict, List
def parse_row(row: Dict) -> Dict:
row['price'] = float(row['price']) / 100.0
return row
def extract_features(rows: List[Dict]) -> List[Dict]:
return [parse_row(r) for r in rows]
Recipe 3 — PHP: pure helper + adapter
<?php
function compute_discount(array $item): array {
$item['discounted'] = $item['price'] * 0.9;
return $item;
}
$items = [['id'=>1,'price'=>100], ['id'=>2,'price'=>200]];
$result = array_map('compute_discount', $items);
echo json_encode($result);
?>
Recipe 4 — Property-based test (Python)
# See the Hypothesis example in the testing section above
Recipe 5 — Property-based test (JS)
// See the fast-check example in the testing section above
Recipe 6 — AI-assisted workflow (conceptual)
- Prompt the AI for a pure function and include edge cases.
- Run unit & property-based tests on the returned code.
- Refactor into smaller functions if needed, and isolate effects into adapters.
- Only merge after tests and code review pass.
For production use, host these examples in a small GitHub repo and add CI to run tests automatically.
Case studies & production stories
Mini case study (anonymized)
A data team converted ETL transforms to pure functions and isolated DB writes into adapters. Over six months they reported:
- 28% reduction in production bugs in pipeline jobs
- Faster issue reproduction via replayable transforms
- Simpler code reviews and fewer incidents
Public-style example
Telecom and messaging systems often use Erlang/Elixir and FP patterns (actor model + supervision) to maintain uptime and simplify failure recovery.
Tools, libraries & resources (2025)
- Languages: Haskell, OCaml, Elixir, Scala, F#, JavaScript, Python, PHP
- JS libraries: Ramda, Lodash/fp
- Python: toolz, Hypothesis (property testing)
- JS testing: fast-check (property testing)
- Effect systems research: algebraic effects materials and tutorials
- AI tools: a range of coding assistants and Copilot alternatives (choose hosted vs self-hosted based on risk)
Internal links for further reading on this site: LogicalMantra home • First Programming Language to Learn in 2025 • Best AI Tools for Developers 2025 • GitHub Copilot Alternatives
Further reading & references
- Hypothesis — property-based testing for Python
- fast-check — property-based testing for JavaScript
- Algebraic effects tutorials and lecture notes
- WebAssembly state and toolchain updates (2024–2025)
- Surveys of AI coding assistants and Copilot alternatives
When you publish, link to specific authoritative pages and any public case study references you cite.
Conclusion & 5-step action checklist
Functional programming is practical in 2025 when used pragmatically: put purity in the core, isolate effects, use property-based testing, and let AI assist but not replace verification. The result: safer concurrency, more testable pipelines, and clearer reasoning about state.
5-step checklist
- Pick a small stateless module (ETL transform or validator).
- Extract pure functions and add unit tests.
- Add property-based tests for important invariants.
- Isolate effectful code into adapters (DB, network, file IO).
- Use AI to suggest refactors but require tests and code review before merging.
Further Reading
- Functional Programming – MDN Web Docs — Beginner-friendly explanation of functional programming for JavaScript developers.
Frequently Asked Questions (FAQs)
1. What is the Functional Programming Paradigm?
Functional Programming (FP) is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids changing state or mutable data.
2. Why is the Functional Programming Paradigm important in 2025?
In 2025, FP is crucial for building scalable, concurrent, and AI-driven applications because it promotes immutability, pure functions, and easy parallelization.
3. What are the core principles of the Functional Programming Paradigm?
The main principles include pure functions, immutability, first-class and higher-order functions, declarative code, and avoiding side effects.
4. How is the Functional Programming Paradigm different from Object-Oriented Programming (OOP)?
FP focuses on functions and immutability, whereas OOP revolves around objects and state. FP is better suited for concurrency and functional composition, while OOP excels in modeling real-world entities.
5. Which programming languages support the Functional Programming Paradigm?
Languages like Haskell, Scala, Clojure, F#, Elixir, and modern languages like Python, JavaScript, and Kotlin partially support FP features.
6. How does AI impact the Functional Programming Paradigm?
AI-driven development tools automate FP code generation, optimize functional pipelines, and enable parallel processing for machine learning tasks, making FP even more relevant in AI-centric software engineering.
7. What are the real-world applications of the Functional Programming Paradigm?
FP is widely used in big data processing, financial systems, distributed systems, AI workflows, and reactive programming due to its ability to handle concurrency and maintain data integrity.