

Fast API vs Flask: Which Python framework should you choose in 2025?
TL;DR: FastAPI is the go-to choice in 2025 for high-concurrency, strongly-typed APIs and AI/ML model serving (auto OpenAPI, async I/O, Pydantic v2 speed). Flask remains ideal for tiny services, prototypes, and legacy WSGI stacks where developer familiarity and extension maturity matter. Benchmark your real workload — DB or model latency usually dominates raw framework differences.
At a glance: FastAPI vs Flask (quick comparison table)
fast api vs flask — quick snapshot. This quick reference helps readers and search engines find the key differences fast.
| Area | FastAPI | Flask |
|---|---|---|
| First released | 2018 (Sebastián Ramírez) | 2010 (Armin Ronacher / Pallets) |
| Core design | ASGI, async-first (Starlette) | WSGI-first, synchronous |
| Auto docs & OpenAPI | Built-in (Swagger UI / ReDoc) | Add-on via extensions |
| Validation | Pydantic (v2 performance gains) | Manual / Marshmallow / WTForms |
| Typical use cases | APIs, ML model serving, microservices, high concurrency | Prototypes, small apps, legacy systems |
| Ecosystem maturity | Rapidly growing (Starlette / Pydantic) | Very mature, many extensions |
| Typical hosting | Uvicorn / Gunicorn+Uvicorn workers, serverless adaptors | Gunicorn / uWSGI, PaaS & serverless adaptors |
What is FastAPI? (quick primer)
FastAPI is a modern, fast (high-performance) Python web framework focused on building HTTP APIs using standard Python type hints. Built on top of Starlette (an ASGI toolkit) and Pydantic for data validation, FastAPI’s design centers on developer productivity, runtime correctness, and performance. It automatically generates OpenAPI (Swagger) documentation from your typed endpoints and models, and encourages non-blocking (async) patterns so a single process can handle many concurrent I/O-bound requests efficiently. FastAPI became popular quickly after its public release because it lets teams ship typed, documented APIs with less ceremony than older frameworks.
Key features
- Async/ASGI-first: write
async defhandlers that integrate with ASGI servers (Uvicorn, Hypercorn). - Pydantic-based validation: request and response models declared as typed
BaseModels are validated automatically; schemas are exported as JSON Schema. - Dependency injection: lightweight DI system for databases, auth, and shared resources.
- Automatic OpenAPI docs:
/docs(Swagger) and/redocendpoints are generated out of the box.
Typical use cases and who uses it
FastAPI shines for:
- APIs with high concurrency such as webhooks, streaming, or services with many small requests.
- ML/AI model serving where typed endpoints and async batching patterns increase throughput and reliability.
- Microservices and API-first architectures that benefit from strong contracts and auto-generated client code.
What is Flask? (quick primer)
Flask is a minimal, flexible microframework for Python that prioritizes developer simplicity and extensibility. Launched in 2010, Flask’s tiny core and strong extension ecosystem made it the go-to for small web apps and prototypes. Flask is WSGI-based and synchronous by default, which aligns well with many traditional web apps and the majority of Python libraries written for synchronous execution.
Key features
- Minimal core: templating (Jinja2), routing, and explicit tools to extend as needed.
- Proven extension ecosystem: ORMs, auth, admin panels, and countless plugins are available for common web needs.
- Easy onboarding: lower initial complexity for simple apps without forcing type systems or DI patterns.
Typical use cases
Flask is ideal for rapid prototyping and MVPs where low ceremony matters, small SaaS apps where synchronous code and mature extensions speed development, and legacy systems where migration costs are high.
Core differences explained (developer POV)
In 2025, choosing between fastapi vs flask is rarely only about raw “speed”. It’s about workload type, team skills, future roadmap (AI/ML), and ecosystem constraints. Below we explain the major developer-facing differences and why they matter.
FastAPI async vs Flask sync: ASGI (FastAPI) vs WSGI (Flask)
ASGI (Asynchronous Server Gateway Interface) is designed to handle concurrently many I/O-bound tasks (HTTP requests, WebSockets, background jobs) within the same process using async/await. FastAPI’s ASGI foundation means endpoints can perform non-blocking waits (network calls, GPU inference orchestration, streaming) without tying up a worker thread.
WSGI (Web Server Gateway Interface) was built for synchronous request/response cycles. Each request typically occupies a thread/process until it finishes. With proper worker sizing (Gunicorn + worker processes or greenlet-based workers), WSGI stacks can scale but often need more CPU/memory when handling many concurrent slow I/O operations.
Practical rule: if your app spends most time waiting on external I/O (DB, remote APIs, model inference queues), ASGI + FastAPI is usually more resource-efficient at high concurrency. If your app is CPU-bound or low-concurrency, Flask remains perfectly fine.
Type system & validation: Pydantic types → fewer runtime errors
FastAPI’s tight integration with Pydantic moves schema and validation mistakes from runtime into contract time. With typed request bodies and responses you get early validation, clearer error messages, auto-generated JSON Schemas, and better IDE hints. Pydantic v2 brought notable performance improvements and API changes, so teams upgrading must follow migration guides thoroughly.
Built-in OpenAPI + docs vs add-ons
FastAPI ships OpenAPI generation and interactive docs out-of-the-box — this reduces friction for API-first teams: clients can test endpoints, generate SDKs, and use live docs as living documentation. Flask can provide similar features, but it requires third-party libraries and maintenance.
Extensibility & ecosystem
Flask’s plugin ecosystem is mature and abundant due to a decade of community contributions. FastAPI’s ecosystem is younger but grows quickly and leverages Starlette and Pydantic; this combination is particularly attractive for AI/ML teams that need typed models and async I/O.
Learning curve & developer experience
Flask is easier to pick up for tiny apps with minimal patterns to learn. FastAPI introduces typing and DI patterns that have a learning cost but yield fewer runtime bugs and clearer contracts — an investment many teams prefer for long-lived APIs or APIs consumed across teams.
Performance & benchmarks: fair testing in 2025
Benchmarks are useful but often misused. Below is how to treat them and a practical plan to benchmark fastapi vs flask performance for your real workload.
What benchmark numbers actually measure and common pitfalls
- Many benchmarks use trivial endpoints (e.g.,
return {"ok": True}) — these measure framework overhead, not real workloads. - Environment matters: OS, server (Uvicorn, Gunicorn, uWSGI), worker configuration, and CPU topology change results dramatically.
- Dependency costs dominate: database queries, caching layers, and model inference usually dominate latency and throughput.
- Cold starts vs warm runs: serverless cold starts (image pull + app start + model load) can dwarf microsecond-level framework differences.
Example benchmark plan (tools, workloads, concurrency, cold starts)

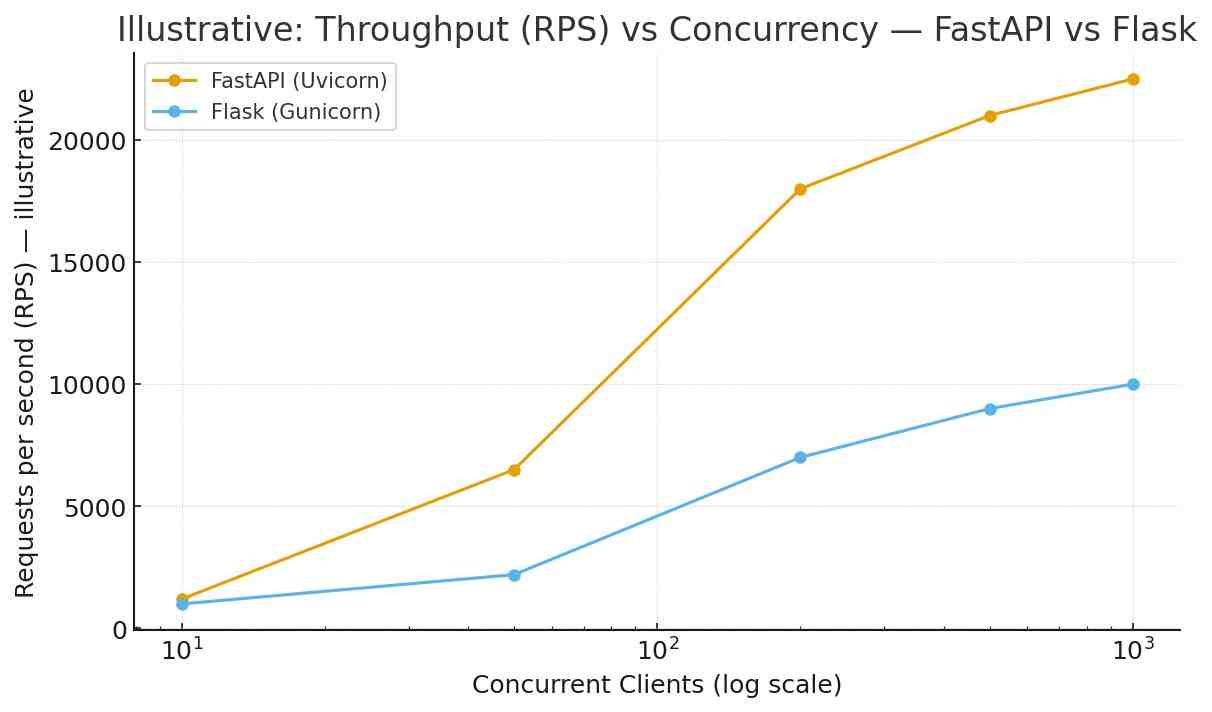
- Test types
- Microbenchmark: simple JSON endpoint to measure framework overhead.
- I/O-bound: simulate DB latency using
await asyncio.sleep(0.05)or a DB proxy. - Model-bound: simulate inference time (50ms CPU or 15–200ms GPU warm inference).
- Tools:
wrk,hey,locust,k6. - Config: test cold-starts and warm runs; try concurrencies 10 / 200 / 1000.
- Repeat: run scenarios multiple times, record medians and p50/p95/p99 latencies.
Sample command (wrk):
wrk -t8 -c200 -d30s http://your-host/predictRealistic results: when FastAPI wins and when Flask is “good enough”

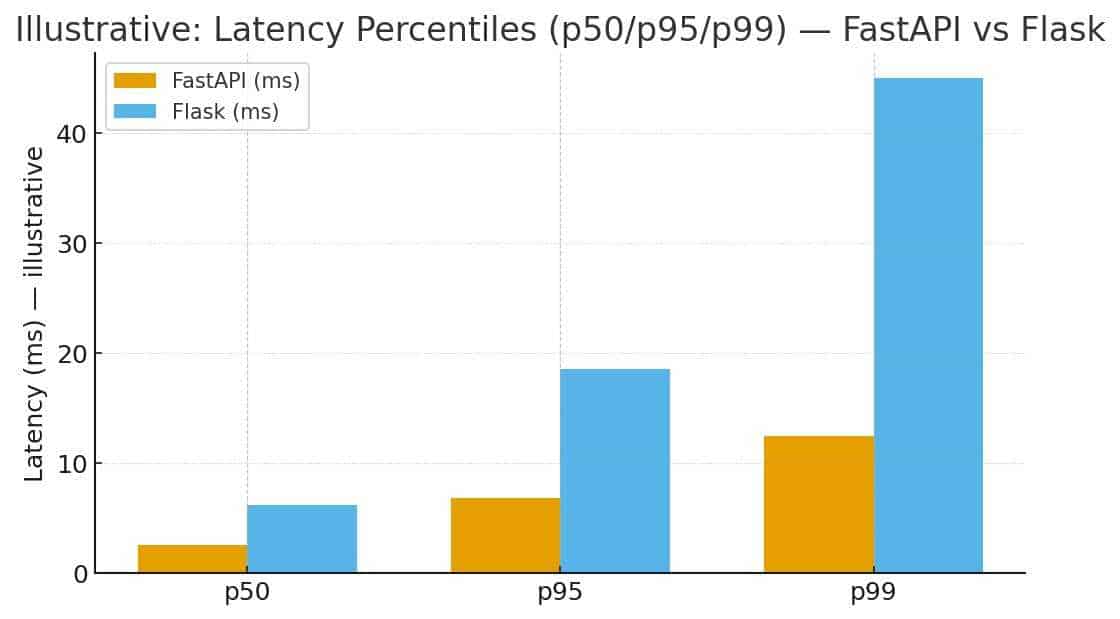
FastAPI typically wins on raw framework+server latency for lightweight JSON endpoints under high concurrency because ASGI servers like Uvicorn perform well. However, when backend latency is dominated by DB calls or model inference, both frameworks behave similarly. Flask configured with optimal Gunicorn workers (or greenlet workers) can handle substantial loads and is often “good enough” for many business needs.
Illustrative benchmark table (example; run your tests for true numbers):
| Scenario | FastAPI (Uvicorn) RPS | Flask (Gunicorn) RPS | Notes |
|---|---|---|---|
| Simple JSON echo (200 conc.) | ~18,000 | ~6,000–8,000 | ASGI event loop and serialization optimizations help FastAPI. |
| DB-bound (50ms DB) | ~1,500 | ~1,400 | DB latency dominates; frameworks similar. |
| ML-inference (50ms CPU) | ~1,300 | ~1,250 | Model inference dominates; frameworks similar. |
Important: the table above shows illustrative values. Run your benchmark plan using your real model/DB to see actual differences for your workload.
Production considerations: scalability, hosting, and cost
Choosing between fastapi vs flask in production requires more than microbenchmark numbers — consider operations, cost, deployment targets, and team skill sets.
ASGI servers (Uvicorn, Hypercorn) vs WSGI servers (Gunicorn)
FastAPI: use uvicorn (ASGI) for best performance; for process management use Gunicorn with uvicorn.workers.UvicornWorker or run Uvicorn with a supervisor/systemd manager. For high availability use multiple replicas behind a load balancer.
Flask: Gunicorn or uWSGI are standard; consider gevent or Meinheld worker classes for higher concurrency. Many PaaS providers support WSGI deployments out of the box.
Production tip: measure CPU and memory footprints under realistic load — FastAPI may require fewer worker processes for I/O-bound workloads, which can reduce container count and cost in autoscaled environments.
Containerization, autoscaling, and resource footprints

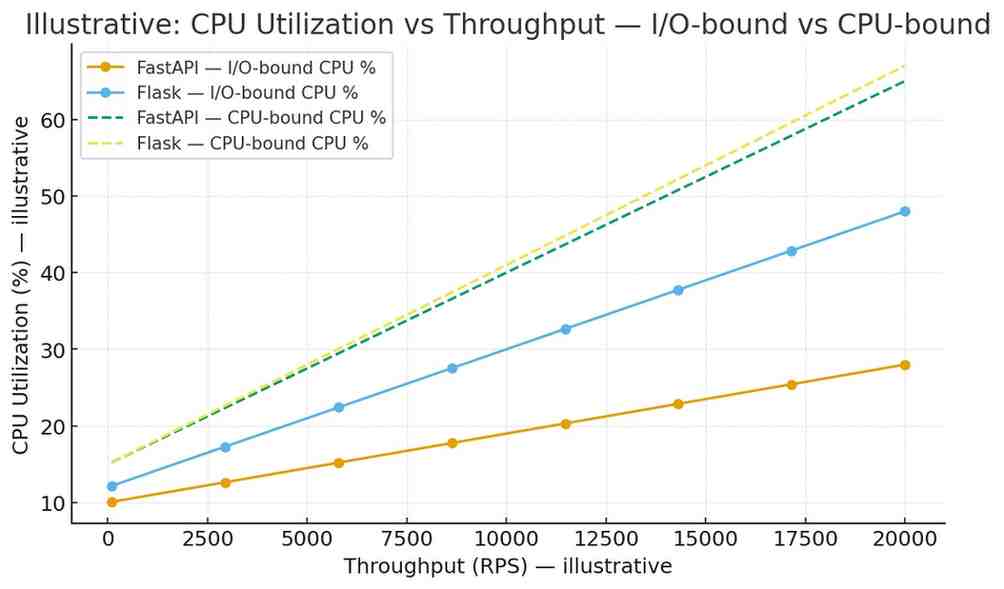
Use multi-stage Docker builds to keep images small. Tune worker counts based on latency/SLA rather than synthetic RPS. Autoscale on meaningful metrics (p95 latency, CPU util, queue depth) and avoid autoscaling solely on RPS.
Serverless & edge: adaptors and tradeoffs
Both frameworks can run serverless, but cold-start overhead (image pull, app init, model load) is the main cost for ML/AI workloads. To reduce impact consider warm containers, provisioned concurrency, or dedicated inference services. FastAPI’s async model helps when mixing short non-blocking tasks and long-lived requests; Flask can be used but may require additional glue for async behavior.
Observability: logging, metrics, tracing
Implement structured logs, per-endpoint metrics and distributed tracing (OpenTelemetry). FastAPI’s strong route typing makes adding per-endpoint metrics more straightforward; Flask requires more manual instrumentation or additional middleware.
Security checklist for APIs (2025)
Security is non-negotiable — whether you choose fast api vs flask, follow this checklist to protect your APIs in 2025.
- Auth & tokens (OAuth2, JWT, sessions): Use established libraries. FastAPI has clear docs for OAuth2 flows; Flask has mature extensions but choose carefully.
- Input validation & schema enforcement: Use schema-first validation (Pydantic or Marshmallow) to reduce injection and type errors.
- Rate limiting & throttling: Apply per-user and per-IP limits with a centralized store (Redis).
- Dependency & supply-chain security (SBOM): Pin dependencies, track Pydantic v2 migration implications, scan for vulnerabilities.
- OWASP API Top 10 mitigations: validate inputs, enforce least privilege, protect fields, use TLS, configure CORS carefully, and log suspicious activity.
- Secrets management: use Vault or cloud secret stores, do not bake secrets into images.
- Testing & contract validation: include OpenAPI spec checks in CI to detect accidental breaking changes.
AI & ML usage: Why FastAPI often becomes the API layer for models (2025 perspective)
In 2025, many production ML systems use FastAPI as the façade for model endpoints due to typed schemas, async patterns, and auto-generated docs. These features streamline collaboration between data scientists, engineers, and client teams.
Async inference, request batching and GPU workloads
FastAPI’s async capabilities let you implement non-blocking batching queues: accumulate requests for a short window, run a batched GPU inference, and return results without blocking worker threads. This pattern improves GPU utilization and overall throughput while keeping latency fallbacks under control.
Autogenerated docs → easier model endpoint discovery
Auto-generated OpenAPI docs make endpoints discoverable to data scientists and QA. When model inputs and outputs are typed, consumers can generate clients and test payloads automatically, reducing integration friction.
Example: serving an LLM embedder / vector search endpoint (FastAPI)
# fastapi_embed.py
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
app = FastAPI(title="Embedder API")
class TextIn(BaseModel):
texts: List[str]
class EmbedsOut(BaseModel):
vectors: List[List[float]]
@app.post("/embed", response_model=EmbedsOut)
async def embed(req: TextIn):
# Pseudo-code: async batcher / vectorizer
# embeddings = await some_async_embedder(req.texts)
embeddings = [[0.01, 0.02]] * len(req.texts) # placeholder
return {"vectors": embeddings}
This example shows how Pydantic models make API contracts explicit — an important property when multiple teams or external clients consume model outputs. AI-assisted tooling can scaffold endpoints, generate tests, and produce example payloads for OpenAPI.
Migration guide: moving from Flask to FastAPI
If you plan to migrate flask to fastapi, use a pragmatic approach that reduces risk while delivering benefits.
When to migrate
Migrate when you see sustained concurrency bottlenecks, want typed request/response contracts, or build new modules centered on AI/ML that require asynchronous flows.
Step-by-step migration checklist
- Audit dependencies: list Flask extensions and check for ASGI-compatible alternatives.
- Design API contract: define OpenAPI and Pydantic models before porting handlers.
- Map Blueprints → APIRouters: move routes to
APIRouterin FastAPI and preserve paths. - Replace validation: convert manual
request.jsonparsing to typed Pydantic models. - Handle blocking code: keep CPU-bound functions in background workers or use
run_in_executor. - Session/auth migration: switch to JWT or shared session stores when appropriate.
- Testing: run both old and new endpoints, add contract tests and OpenAPI checks.
- Staged rollout: route a portion of traffic to the new service and monitor key metrics.
Pitfalls & gotchas
- Extensions relying on WSGI internals may not have direct equivalents; plan replacements.
- Moving sync code into async handlers without care can cause thread-pool exhaustion or blocking issues.
- Follow Pydantic v2 migration guides carefully — some API patterns changed.
Before / after snippet
# Flask (before)
@app.route("/predict", methods=["POST"])
def predict():
data = request.json
# manual validation...
return jsonify({"pred": model.predict(data)})
# FastAPI (after)
from pydantic import BaseModel
class In(BaseModel):
features: List[float]
@app.post("/predict")
async def predict(payload: In):
return {"pred": model.predict(payload.features)}
Testing, CI/CD and contract testing
Robust CI and contract testing reduce rollout risk and ensure that switching frameworks doesn’t introduce regressions.
Unit & integration tests
Use pytest. For FastAPI use TestClient or httpx.AsyncClient to test endpoints. Write tests that validate request/response shapes using Pydantic models so schema changes fail tests early.
Contract testing
Export your OpenAPI spec from FastAPI and use it for consumer-driven contract tests (PACT or similar). Include OpenAPI snapshot comparisons in CI to detect unexpected breaking changes.
CI pipeline checklist
- Lint:
ruff/flake8 - Typecheck:
mypy(if you use typing) - Pydantic validation smoke tests
- OpenAPI snapshot & diff checks
- Performance smoke tests (lightweight)
Real world case studies & sample apps
Mini case study 1: High-throughput API — FastAPI chosen
A data platform moved core API routes to FastAPI to exploit async DB calls and background batching. The migration reduced required worker count by ~30% and stabilized p95 latency during traffic spikes. Auto-generated docs reduced integration time for analytics consumers.
Mini case study 2: Small SaaS prototype — Flask for velocity
A two-person startup built their MVP in Flask in a single sprint using Flask-Login, Flask-Migrate, and SQLAlchemy. Time to first revenue was prioritized; the stack remained Flask for initial years and only later migrated high-traffic endpoints to FastAPI.
Mini case study 3: ML model serving — FastAPI for async batching
A company serving embeddings used FastAPI to implement a batched inference queue that aggregated requests for 50ms, ran a batched GPU inference, and returned responses. The batched path increased GPU utilization significantly while keeping latency within SLA.
Decision matrix: When to pick FastAPI, Flask, or keep both
| Need / Constraint | Pick FastAPI | Pick Flask |
|---|---|---|
| High concurrency / async I/O | ✅ | |
| ML model serving / batching | ✅ | |
| Quick prototype / low complexity | ✅ | |
| Large legacy WSGI ecosystem | ✅ | |
| Strong typed contracts / auto OpenAPI | ✅ | |
| Small team without typing experience | ✅ |
Short rules: pick FastAPI when you expect growth, concurrency, or need strong API contracts for many consumers. Keep Flask if fast development and extension availability for small apps outweigh future scaling needs. Use a hybrid approach where appropriate.
Code snippets appendix / cheat sheet
Simple REST endpoint — Flask
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/hello")
def hello():
return jsonify({"msg": "hi"})Same endpoint — FastAPI (typed)
from fastapi import FastAPI
app = FastAPI()
@app.get("/hello")
async def hello():
return {"msg": "hi"}Add OpenAPI metadata (FastAPI)
app = FastAPI(title="My API", version="1.0.0", description="An API for demos")WebSocket (FastAPI)
from fastapi import WebSocket
@app.websocket("/ws")
async def websocket_endpoint(ws: WebSocket):
await ws.accept()
await ws.send_text("connected")
await ws.close()Blueprint → APIRouter (Flask → FastAPI mapping)
# Flask blueprint
bp = Blueprint('auth', __name__)
@bp.route('/login')
def login(): ...
# FastAPI router
from fastapi import APIRouter
router = APIRouter(prefix="/auth")
@router.post("/login")
async def login(): ...
app.include_router(router)FAQs (target keyword variants)
Is FastAPI faster than Flask?
Short answer: usually for I/O-bound, high-concurrency endpoints due to ASGI and async I/O. For DB or model-heavy endpoints the difference shrinks — real-world bottlenecks dominate.
Can I use Flask async functions?
Flask added some async support, but its ecosystem and server model remain WSGI-centric. You can run async code but it’s not as seamless or battle-tested as in ASGI frameworks. Consider compatibility and extension support before relying on async in Flask.
Is migrating from Flask to FastAPI worth it?
Migrate when you need async I/O, typed contracts, or targeted ML/AI serving features. If your Flask stack meets current performance and feature needs, postpone migration or adopt a staged approach.
How does Pydantic v2 affect me?
Pydantic v2 brings API changes and performance improvements — follow the official migration guide and verify model behaviors in tests; the speedups are often worth the migration effort for schema-heavy apps.
Resources & further reading
- FastAPI official docs For a practical learning path covering backend, deployment, and CI/CD, see our Full-Stack Developer Roadmap in 2025. To understand the AI trends shaping model deployment choices, read Artificial Intelligence vs Human Intelligence in 2025.
Conclusion & recommended next steps
TL;DR decision:
- Choose FastAPI if you’re building high-concurrency APIs, serving ML/AI models, or need strong typed contracts with auto-generated docs.
- Choose Flask if you need the fastest path to an MVP, rely on mature extensions, or operate within an established WSGI ecosystem.
- Hybrid approach: keep parts that work (Flask) and extract new, high-performance services into FastAPI as needed.
Actionable next steps
- Pick one representative endpoint (DB or model-backed).
- Implement a FastAPI version and run the benchmark plan (micro + DB + model).
- Measure p50/p95/p99, CPU, and memory under real traffic.
- If results justify, migrate high-value endpoints first and instrument heavily.